Cuando uno empieza a trabajar con Python para analítica de datos, comienza a programar con la librería Numpy, que está pensada en principio para datos de tablas numéricos con tipos homogéneos.
Sin embargo, la ventaja de la librería PANDAS frente a Numpy es que la primera está pensada desde un comienzo en datos tabulares heterogéneos.
Pandas es un proyecto de código abierto y gestionado por su comunidad de desarrolladores.
Vamos a ver un pequeño ejemplo de PANDAS, donde todas las funciones están pensadas en tablas, sin la utilización de bucles for … esto es fundamental!!!
Para dicho ejemplo utilizaremos el objeto #DataFrame, que tiene un índice de fila y otro de columna, a modo de un diccionario de objetos #Series que tienen todos idéntico el índice.
Por convención, usaremos el la siguiente codificación para importar Numpy y Pandas. Y será el comienzo de nuestro script con un montón de prints para que podamos ver los resultados por pantalla a modo de traza:
print(«# Método pandas.DataFrame.reindex»)
print(«# Trabajando con Pandas»)
import numpy as np
import pandas as pd
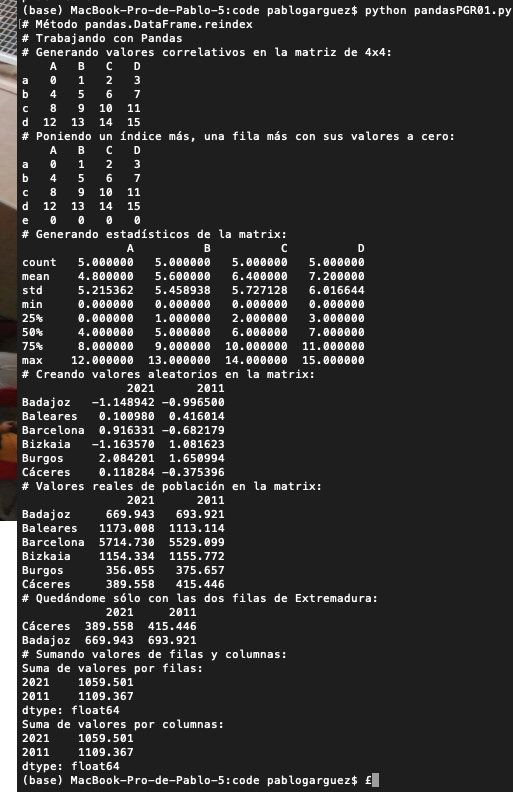
A continuación con DataFrame generaremos una matriz de 4×4 con valores correlativos del 1 al 16:
print(«# Generando valores correlativos en la matriz de 4×4:»)
data = pd.DataFrame(np.arange(16).reshape((4,4)), index=[«a», «b», «c», «d»], columns=[«A», «B», «C», «D»])
print(data)
En nuestro ejemplo, para manejo de datos con PANDAS crearemos una nueva fila (una 5ª fila) donde pondremos todos los valores a CERO:
print(«# Poniendo un índice más, una fila más con sus valores a cero:»)
datos_conCeros = data.reindex(index=[«a», «b», «c», «d», «e»], fill_value=0)
print(datos_conCeros)
El resultado sería:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
0 0 0 0 0
Con la función describe() generamos distintos estadísticos de la última matriz de 5×4:
print(«# Generando estadísticos de la matrix:»)
print(datos_conCeros.describe())
A continuación creamos una matriz con datos aleatorios generados automáticamente, con índices provincias españolas y columnas dos años separados por 10 años (2021 y 2011):
print(«# Creando valores aleatorios en la matrix:»)
datos_aleatorios=pd.DataFrame(np.random.standard_normal((6,2)), index=[«Badajoz», «Baleares», «Barcelona», «Bizkaia», «Burgos», «Cáceres»],
columns=[«2021», «2011»])
print(datos_aleatorios)
Generando así una matrix de 7×3
Ya esa misma matrix con datos reales de número de habitantes (población) de dichas provincias:
print(«# Valores reales de población en la matrix:»)
datos_reales=pd.DataFrame([[669.943, 693.921], [1173.008, 1113.114], [5714.730, 5529.099], [1154.334, 1155.772], [356.055, 375.657], [389.558, 415.446]],
index=[«Badajoz», «Baleares», «Barcelona», «Bizkaia», «Burgos», «Cáceres»], columns=[«2021», «2011»])
print(datos_reales)
Y ya sobre esos valores puedo filtrar las dos provincias extremeñas con la función reindex (REINDEXACIÓN):
print(«# Quedándome sólo con las dos filas de Extremadura:»)
datos_extremadura=datos_reales.reindex(index=[«Cáceres», «Badajoz»])
print(datos_extremadura)
Y a partir de ahí puedo hacer las operaciones que considere a modo de estadísticos. Por ejemplo aquí sumamos valores por provincias para Cáceres y Badajoz en cuanto a su población en los años 2021 y 2011:
print(«# Sumando valores de filas y columnas:»)
suma_filas = datos_extremadura.sum()
suma_columnas = datos_extremadura.sum(axis=»index»)
print(«Suma de valores por filas:»)
print(suma_filas)
print(«Suma de valores por columnas:»)
print(suma_columnas)
Bueno es un ejemplo muy muy sencillo, pero da una idea bastante ilustrativa de la cantidad de posibilidades que tiene la librería PANDAS para INDEXAR Y FILTRAR. Espero que este trozo de código haya conseguido explicarlo un poco aunque sea así por encima …
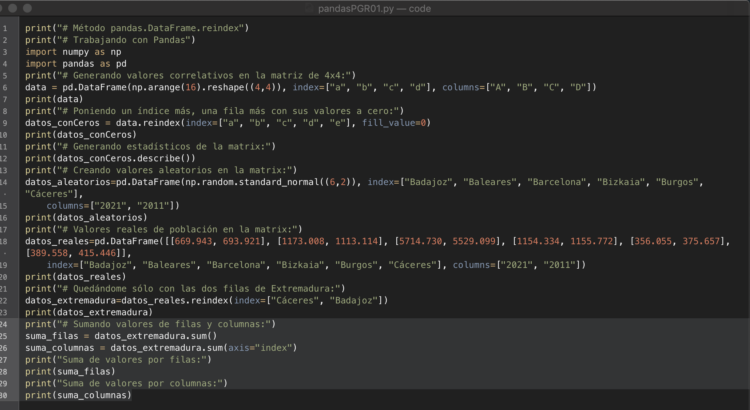
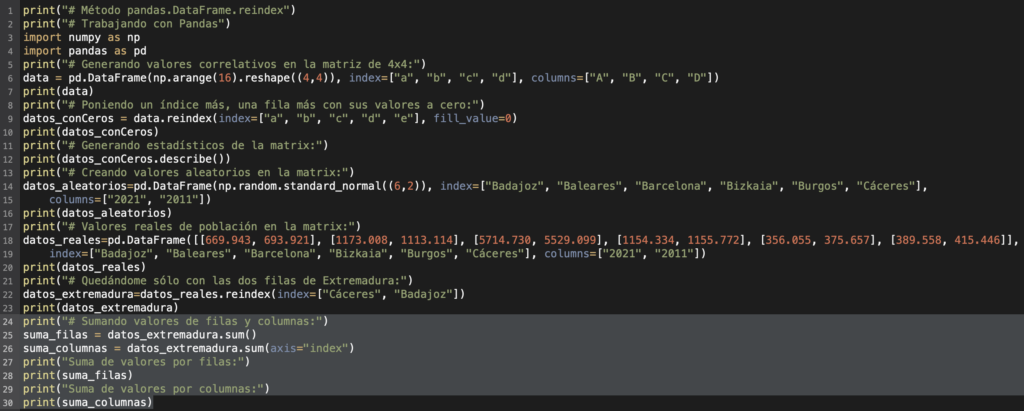
Aquí tenéis el script de Python al completo con el editor de texto TextMate:
Y finalmente el resultado de dicho script mostrando por pantalla lo que hemos obtenido con los distintos prints: