Antes de proceder a cq #AnálisisDeDatos, lo primero de todo es acceder a los datos. Para ello en #pandas lo que tenemos es que pasar esos datos del formato que sea a un objeto #DataFrame con su índice y resto de columnas. A partir de ahí ya limpiaremos esos datos y los prepararemos para su posterior visualización y análisis.
Tenemos que tener en cuenta que en #Python es sencillo en cuanto a su sintaxis pero es extremadamente lento para trabajar con datos, sobre todo las copias en memoria, por muy rápida que sea la CPU.
pandas1 está basado en Python con la libreria #Numpy (numérica) para esa eficiencia on datos, y pandas2 en #ApacheArrows. En cq caso, pandas está bien para trabajar con datos CSV, excell, json, SAP, etc. pero no así por ejemplo para el procesamiento del lenguaje natural o el trabajo con imágenes.
Por tanto, tenemos en primer lugar que #CargarDatos y así lo tenemos es que basarnos en la #EntradaYSalida de datos mediante pandas.
Pandas tiene varias funciones para leer datos y convertirlos en objetos DataFrame. Las más importantes son: read_csv (usa la coma como delimitador preestablecido: “comma separated values”), read_excell, read_clipboard (portapapeles), read_hdf, read_html, read_json, read_parquet (Apache), read_pickle (binarios), read_sas, read_spss, read_sql (SQLAlchemy), read_sql_table, read_xml, etc.
Con pandas se usan varios centinelas cuando no hay datos NULL, NA, NaN (Not a Number) para valores ausentes. Por ejemplo read_csv utiliza más de 50 parámetros diferentes.
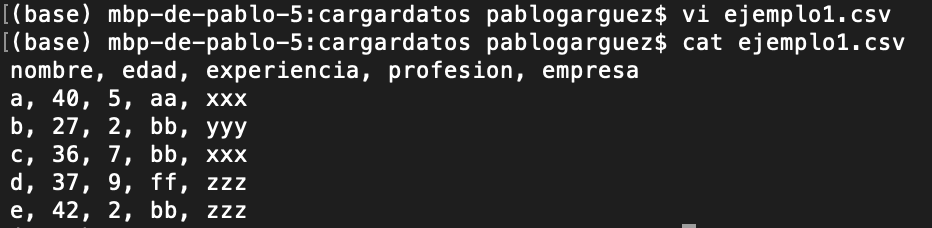
A modo de ejemplo, si tenemos un fichero CSV (“comma separated values”) que se puede visualizar con el comando cat del shell de UNIX:
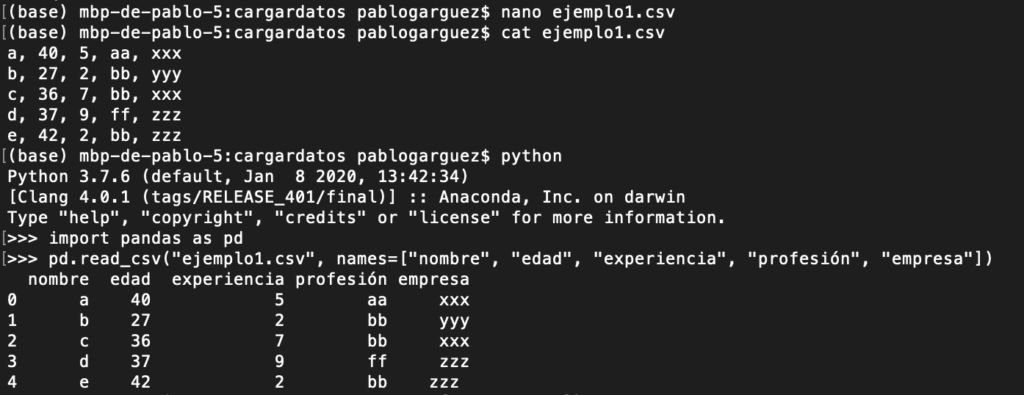
Y con read_csv antes cargamos “import pandas as pd” con lo que pd.read_csv (parametros …):
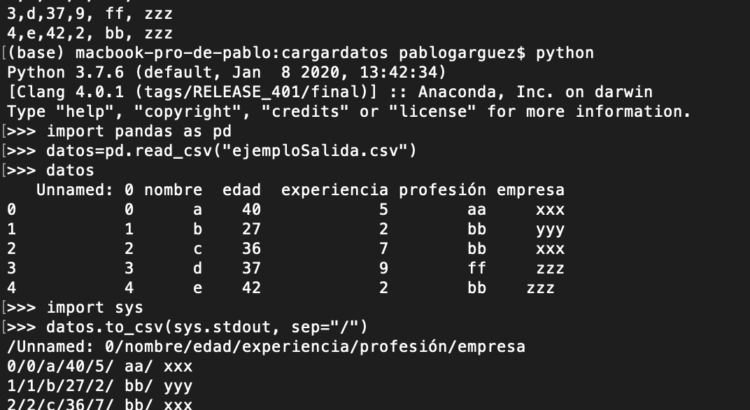
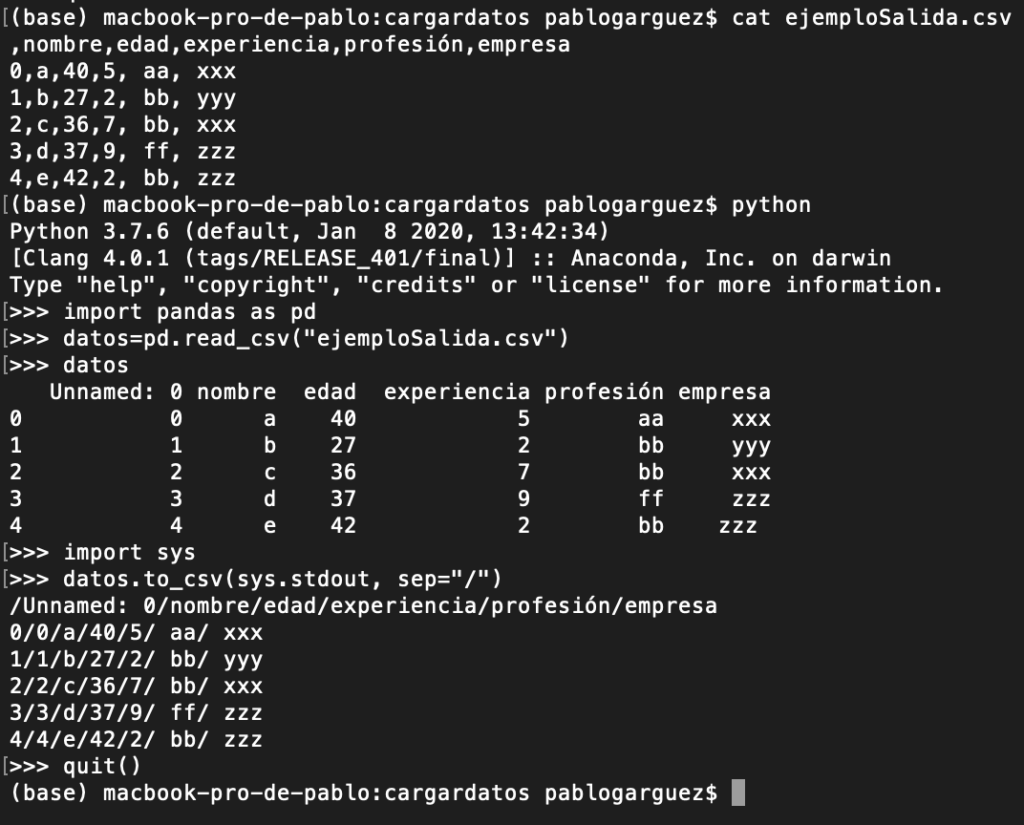
También podemos hacer el proceso contrario de pasar del objeto DataFrame a un fichero CSV con to_csv:
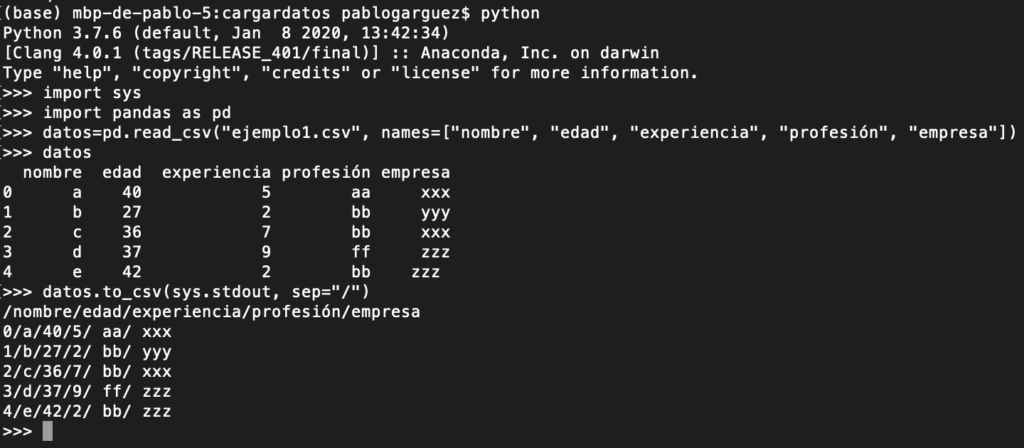
Otra opción sería mostrar los datos por consola con “import sys” con to_csv (sys.stdout, …)
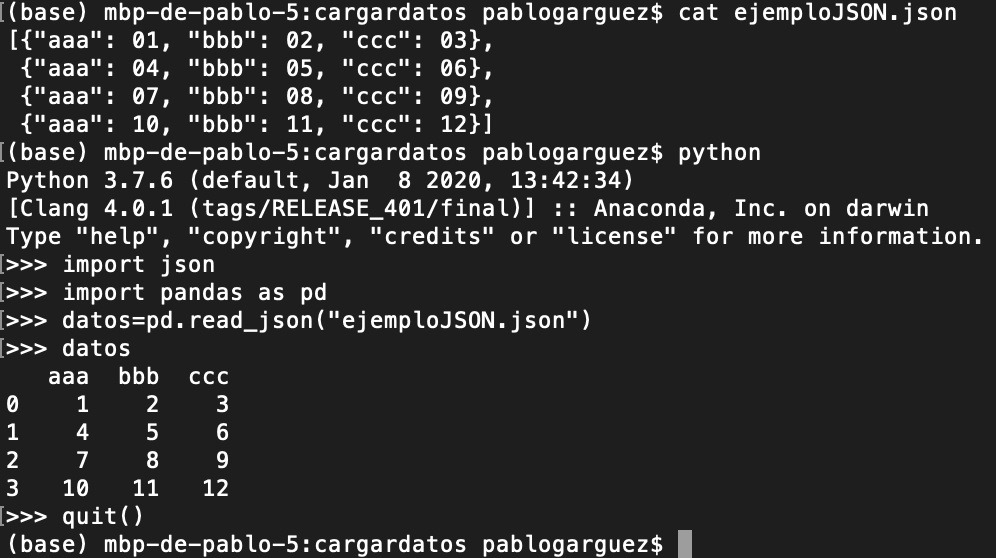
Un último ejemplo con otro formato -> datos JSON (JavaScript Object Notation) para pasar al objeto DataFrame: